🔬Technical Deep Dive
Full Specifications [+]
🚀 What's Next?
🖼️ Visual Gallery
1 Images Detected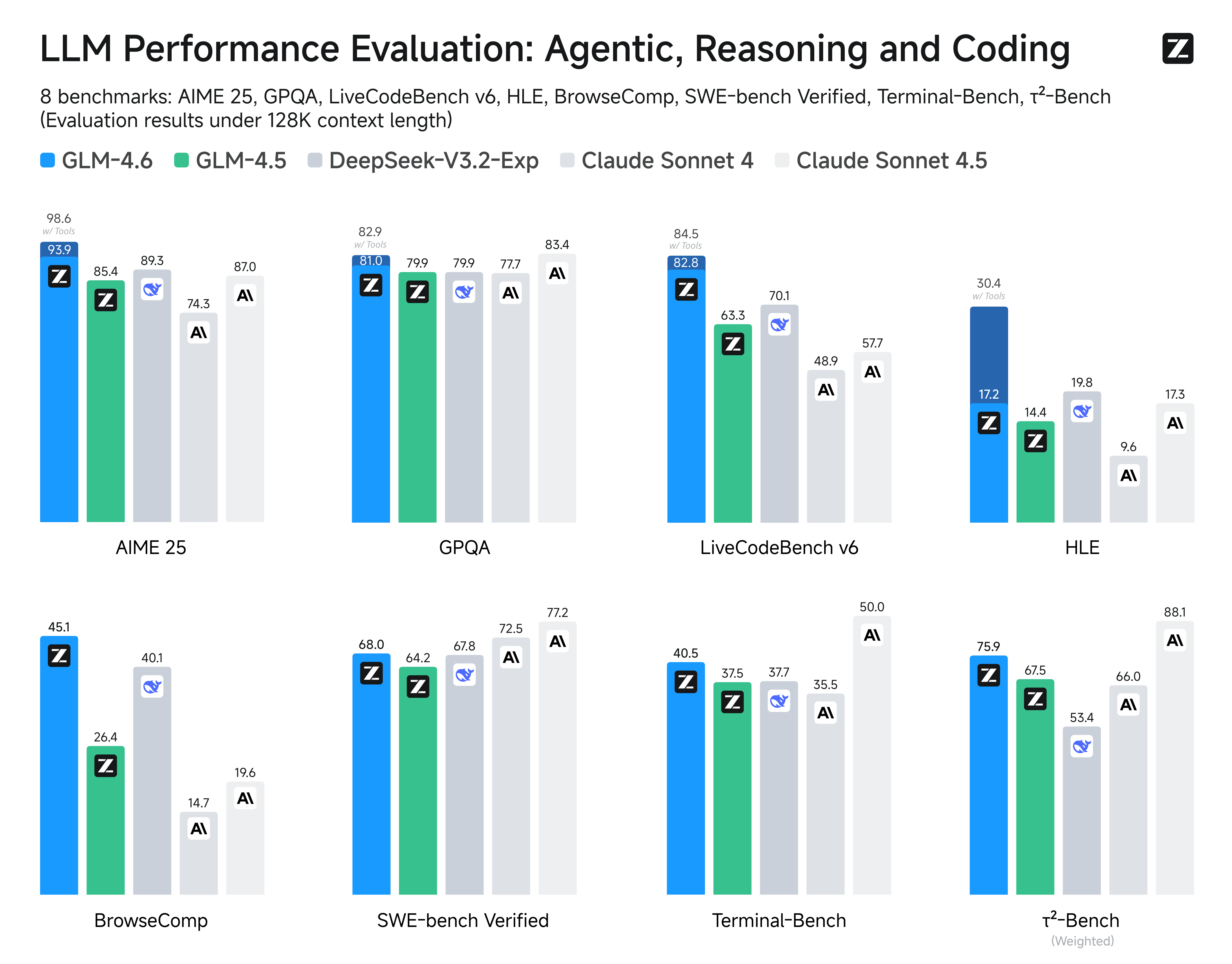
⚡ Quick Commands
huggingface-cli download zai-org/glm-4.6 pip install -U transformers Hardware Compatibility
Multi-Tier Validation Matrix
RTX 3060 / 4060 Ti
RTX 4070 Super
RTX 4080 / Mac M3
RTX 3090 / 4090
RTX 6000 Ada
A100 / H100
Pro Tip: Compatibility is estimated for 4-bit quantization (Q4). High-precision (FP16) or ultra-long context windows will significantly increase VRAM requirements.
README
GLM-4.6
👋 Join our Discord community.
📖 Check out the GLM-4.6 technical blog, technical report(GLM-4.5), and Zhipu AI technical documentation.
📍 Use GLM-4.6 API services on Z.ai API Platform.
👉 One click to GLM-4.6.
Model Introduction
Compared with GLM-4.5, GLM-4.6 brings several key improvements:
- Longer context window: The context window has been expanded from 128K to 200K tokens, enabling the model to handle more complex agentic tasks.
- Superior coding performance: The model achieves higher scores on code benchmarks and demonstrates better real-world performance in applications such as Claude Code、Cline、Roo Code and Kilo Code, including improvements in generating visually polished front-end pages.
- Advanced reasoning: GLM-4.6 shows a clear improvement in reasoning performance and supports tool use during inference, leading to stronger overall capability.
- More capable agents: GLM-4.6 exhibits stronger performance in tool using and search-based agents, and integrates more effectively within agent frameworks.
- Refined writing: Better aligns with human preferences in style and readability, and performs more naturally in role-playing scenarios.
We evaluated GLM-4.6 across eight public benchmarks covering agents, reasoning, and coding. Results show clear gains over GLM-4.5, with GLM-4.6 also holding competitive advantages over leading domestic and international models such as DeepSeek-V3.1-Terminus and Claude Sonnet 4.
Inference
Both GLM-4.5 and GLM-4.6 use the same inference method.
you can check our github for more detail.
Recommended Evaluation Parameters
For general evaluations, we recommend using a sampling temperature of 1.0.
For code-related evaluation tasks (such as LCB), it is further recommended to set:
top_p = 0.95top_k = 40
Evaluation
GLM-4.6
👋 Join our Discord community.
📖 Check out the GLM-4.6 technical blog, technical report(GLM-4.5), and Zhipu AI technical documentation.
📍 Use GLM-4.6 API services on Z.ai API Platform.
👉 One click to GLM-4.6.
Model Introduction
Compared with GLM-4.5, GLM-4.6 brings several key improvements:
- Longer context window: The context window has been expanded from 128K to 200K tokens, enabling the model to handle more complex agentic tasks.
- Superior coding performance: The model achieves higher scores on code benchmarks and demonstrates better real-world performance in applications such as Claude Code、Cline、Roo Code and Kilo Code, including improvements in generating visually polished front-end pages.
- Advanced reasoning: GLM-4.6 shows a clear improvement in reasoning performance and supports tool use during inference, leading to stronger overall capability.
- More capable agents: GLM-4.6 exhibits stronger performance in tool using and search-based agents, and integrates more effectively within agent frameworks.
- Refined writing: Better aligns with human preferences in style and readability, and performs more naturally in role-playing scenarios.
We evaluated GLM-4.6 across eight public benchmarks covering agents, reasoning, and coding. Results show clear gains over GLM-4.5, with GLM-4.6 also holding competitive advantages over leading domestic and international models such as DeepSeek-V3.1-Terminus and Claude Sonnet 4.
Inference
Both GLM-4.5 and GLM-4.6 use the same inference method.
you can check our github for more detail.
Recommended Evaluation Parameters
For general evaluations, we recommend using a sampling temperature of 1.0.
For code-related evaluation tasks (such as LCB), it is further recommended to set:
top_p = 0.95top_k = 40
Evaluation
📝 Limitations & Considerations
- • Benchmark scores may vary based on evaluation methodology and hardware configuration.
- • VRAM requirements are estimates; actual usage depends on quantization and batch size.
- • FNI scores are relative rankings and may change as new models are added.
- ⚠ License Unknown: Verify licensing terms before commercial use.
- • Source: Unknown
Cite this model
Academic & Research Attribution
@misc{hf_model__zai_org__glm_4.6,
author = {zai-org},
title = {undefined Model},
year = {2026},
howpublished = {\url{https://huggingface.co/zai-org/glm-4.6}},
note = {Accessed via Free2AITools Knowledge Fortress}
}AI Summary: Based on Hugging Face metadata. Not a recommendation.
🛡️ Model Transparency Report
Verified data manifest for traceability and transparency.
🆔 Identity & Source
- id
- hf-model--zai-org--glm-4.6
- author
- zai-org
- tags
- transformerssafetensorsglm4_moetext-generationconversationalenzharxiv:2508.06471license:mitendpoints_compatibleregion:us
⚙️ Technical Specs
- architecture
- Glm4MoeForCausalLM
- params billions
- 356.79
- context length
- 4,096
- vram gb
- 270.1
- vram is estimated
- true
- vram formula
- VRAM ≈ (params * 0.75) + 2GB (KV) + 0.5GB (OS)
📊 Engagement & Metrics
- likes
- 1,143
- downloads
- 332,556
Free2AITools Constitutional Data Pipeline: Curated disclosure mode active. (V15.x Standard)